Описание алгоритма
Оглавление
Основные подходы
Артефакты
Индекс
Вычисление степени похожести строк
Опции алгоритма
Алгоритм нечеткого поиска TextRadar. Основные подходы
В отличие от нечеткого сравнения строк, когда обе сравниваемые строки равнозначны, в задаче нечеткого поиска выделяются строка поиска и строка данных, а определить необходимо не степень похожести двух строк, а степень присутствия строки поиска в строке данных.Постановка задачи
Даны строка данных и строка поиска как произвольные наборы символов, состоящие из слов – групп символов, разделенных пробелами. Требуется найти в строке данных наиболее близкий к строке поиска по составу и взаимному расположения символов набор фрагментов. Для оценки качества результата поиска вычислить коэффициент релевантности, значение которого должно лежать в диапазоне от 0 до 1, где 0 должен соответствовать полному отсутствию символов строки поиска в строке данных, а 1 – наличию строки поиска в строке данных в неискаженном виде. Поиск должен осуществляться путем посимвольного анализа исходных строк, с учетом взаимного расположения символов и слов в строках, но без учета синтаксиса и морфологии языка.Описание алгоритма
Поиск осуществляется в несколько этапов.Построение матрицы совпадений
Матрица совпадений (M) представляет собой двумерную матрицу, количество столбцов которой соответствует длине строки данных, а количество строк – длине строки поиска. Элементы матрицы совпадений принимают значения 0 или 1 в зависимости от того, совпадают или нет соответствующие символы строк за исключением пробелов (разделителей слов). Матрица совпадений для строки данных «ABCD EF» и строки поиска «ABC» имеет вид:

Элемент матрицы совпадений m(i, j) = 1, если d(i) = s(j), где D – массив символов строки данных, S – массив символов строки поиска, i – номер столбца матрицы совпадений M (номер символа строки данных), j – номер строки матрицы совпадений (номер символа в строке поиска). В остальных случаях m(i,j) = 0. Совпадения разделителей слов (в нашем случае это пробелы) не учитывается, то есть: m(i,j) = 0, если d(i) = s(j) = ‘ ‘.
Диагонали матрицы совпадений
Элементы матрицы совпадений M образуют диагонали. Элементы матрицы находятся на одной диагонали, если их индексы i и j одновременно различаются на +1 или на – 1.
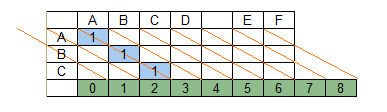
Диагонали соответствуют положениям строки поиска в последовательности сдвигов вдоль строки данных.
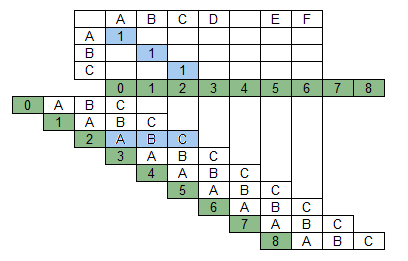
Элементы одной из диагоналей и соответствующий ей сдвиг на рисунке выше выделены синим. Идея использования последовательности сдвигов строк друг относительно друга в задаче нечеткого поиска восходит к хорошо известной методике обнаружения радиолокационных сигналов на фоне помех, которая предполагает вычисление взаимной корреляционной функции радиосигналов. Взаимнокорреляционная функция определяет степень схожести копий двух различных сигналов v(t) и u(t), сдвинутых на время τ друг относительно друга и определяется как интеграл:
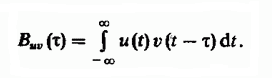
Общее количество диагоналей рассчитывается по формуле:
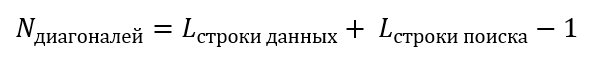
Длины диагоналей равны длине строки поиска.
Группы совпадений
Единицы, следующие подряд в диагоналях матрицы совпадений, образуют группы совпадений. Ниже представлены группы совпадений для строки данных «ABCD DEF JH» и строки поиска «ABC DE J» — 4 группы, находящиеся на разных диагоналях.
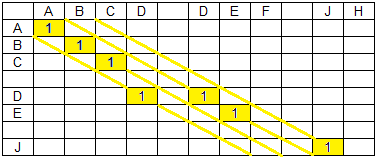
Матрицы проекций
Диагонали матрицы совпадений и содержащиеся в них группы совпадений отображаются на соответствующие участки строки поиска и строки данных, образуя две матрицы проекций – на строку поиска и на строку данных соответственно. Для нашего примера матрицы проекций будут выглядеть следующим образом:
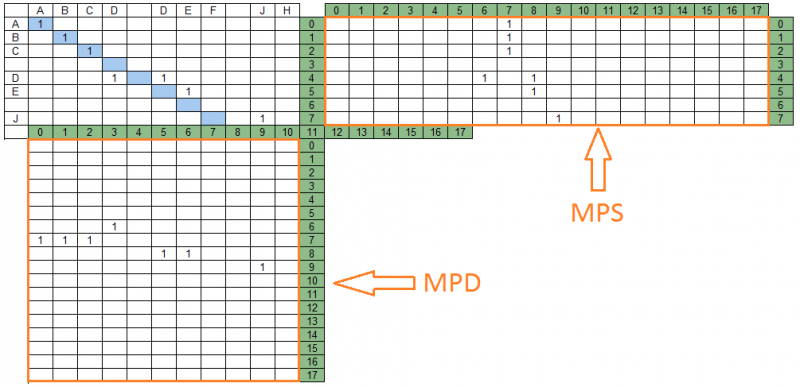
На приведенном рисунке, справа от матрицы совпадений находится матрица проекций на строку поиска - MPS, снизу – матрица проекций на строку данных MPD. Количество столбцов MPS равно количеству строк MPD и равно числу диагоналей матрицы совпадений – в нашем примере их 18.
Поиск результирующего набора групп
Для решения задачи необходимо найти такой набор групп, который наиболее полно «накроет» строку поиска, при этом наименее фрагментировано (максимально крупными частями), без взаимных пересечений в матрицах проекций и отображение которого на строку данных будет наиболее близко к «оригиналу» — строке поиска. Пересечение групп в матрице проекций В нашем примере есть группы, пересекающиеся в матрице MPS – на рисунке ниже они выделены красным. При этом в матрице MPD эти же группы не пересекаются, на рисунке они выделены зеленым.
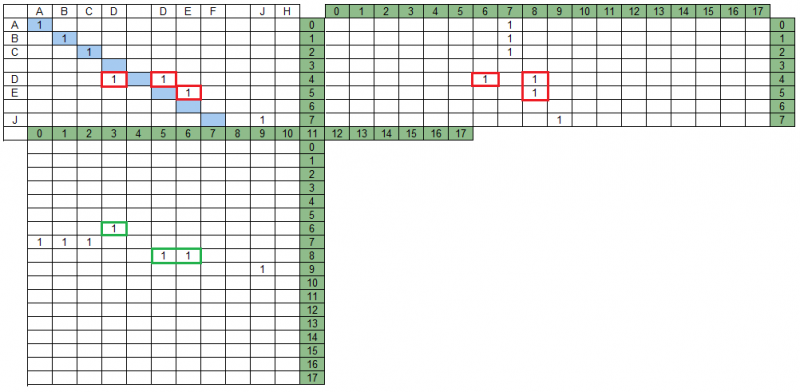
Поиск результирующего набора групп подразумевает, что в него войдут не все группы и что часть из оставшихся групп может быть модифицирована (усечена) при анализе взаимных пересечений групп в проекциях. Поиск результирующего набора может быть осуществлен путем обхода в «бесконечном» цикле (количество итераций цикла не превысит количества групп) таблицы всех групп, в которую изначально помещаются группы матрицы совпадений, на каждой итерации которого будут осуществляться следующие действия:
- Выбор наилучшей по определенным (зависящим от контекста решаемой задачи) параметрам — в самом простом случае это может быть выбор первой попавшейся группы наибольшего размера;
- Помещение лучшей группы в таблицу групп результата и удаление ее из таблицы всех групп (обход строк которой производится);
- Удаление (или усечение) из таблицы групп пересекающихся с выбранной наилучшей группой в матрицах проекций групп.
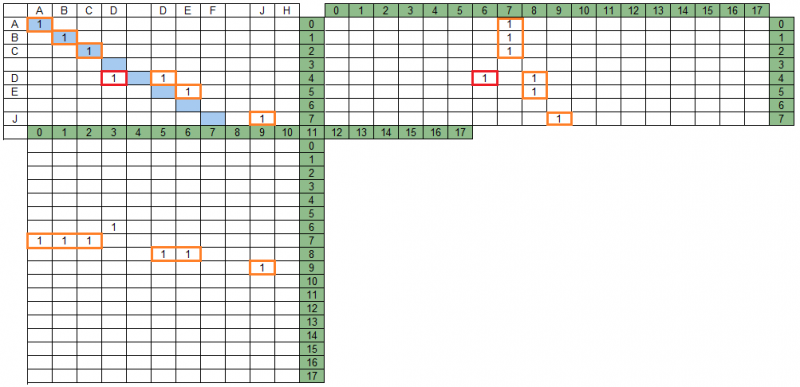
Удаленная в процессе обработки пересечений (пересекающаяся в матрице MPS с наилучшей группой второй итерации) группа выделена красным. Результат поиска в строке данных будет выглядеть так:

Вычисление коэффициента релевантности
Для количественной оценки результатов поиска сопоставляются длины найденных групп с длинами слов строки поиска (оценка состава групп), а также общая длина строки поиска с протяженностью найденных групп в строке данных. При этом предполагается, что значимость оценки состава найденных групп выше значимости оценки протяженности в строке данных, что учтено в весовых коэффициентах формулы расчета коэффициента релевантности:

Где коэффициент состава групп рассчитывается как отношение суммы квадратов длин найденных групп к сумме квадратов длин слов строки поиска:
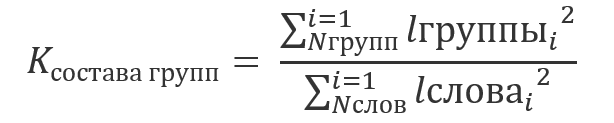
Коэффициент протяженности – как отношение длины строки поиска к общей протяженности найденных групп на строке данных. В случае, если полученное таким образом значение больше 1, берется его обратная величина:
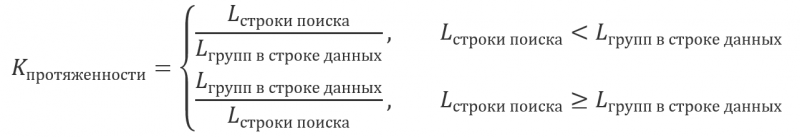
Для нашего примера:
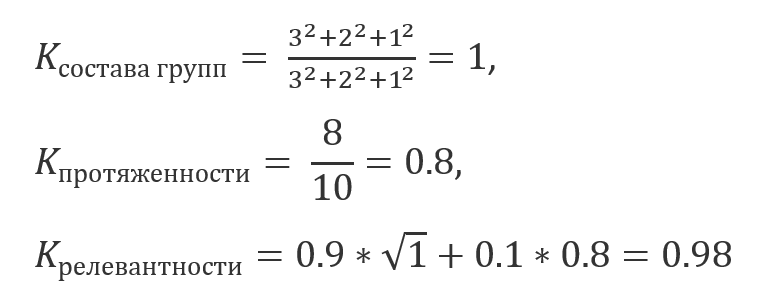
Оценка объема вычислений
Наиболее ресурсоемкими являются операции:
- определение матрицы совпадений M - количество элементов матрицы определяется как произведение длины строки поиска на длину строки данных: Lп * Lд;
- определение матриц проекций на строки данных и поиска — количество элементов матриц составит для MPS: (Lп + Lд – 1) * Lп, для MPD: (Lп + Lд – 1) * Lд;
- формирование таблицы всех групп — количество групп не превысит величины Lп * Lд / 2;
- поиск результирующего набора групп — количество итераций цикла не превысит исходного количества групп, то есть Lп * Lд / 2.

Линейность объема вычислений относительно размера исходных данных является важным аргументом в пользу практического применения алгоритма.
Нелинейность
Стоит отметить, что линейность обусловлена упрощенной процедурой поиска результирующего набора групп. В общем случае, если рассматривать все возможные варианты размещений групп на строке данных с учетом возможных вариантов обработки пересечений и осуществлять выбор наилучшего набора групп из множества возможных, а не выбор одной группы на каждой итерации цикла, то объем вычислений перестанет быть линейным по отношению к размеру исходных данных. Нелинейная зависимость объема вычислений от размера исходных данных сильно ограничивает возможности практического применения.
Находим баланс
Для обеспечения оптимального баланса между качеством поиска и потребностью в ресурсах, важно правильно выбрать методику поиска результирующего набора групп, что как правило удается сделать, используя особенности контекста решаемой задачи.
Сравнение c аналогами: Сравнение алгоритма нечеткого поиска TextRadar c аналогами: Lucene, Sphinx, Яндекс, 1С
Скачать демо-проект с базовой функциональностью (C# ASP.NET MVC) можно здесь: https://github.com/tsaregorodtseff/TextRadar
Алгоритм нечеткого поиска TextRadar. Артефакты
При решении практических задач были выявлены ситуации, когда использование только базовой методики не обеспечивает требуемого качества поиска. В результате были созданы дополнения (опции алгоритма), о которых и пойдет речь.
Фрагменты одного слова строки поиска расположены в нескольких словах строки данных
Пусть строка поиска ABCD, а строка данных — ABCE DFG.
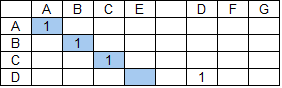
Применение базового алгоритма даст следующий результат:

При возникновении подобных коллизий лишние группы удаляются. Выбор групп для удаления — это отдельный, комплексный вопрос. В результате должны остаться наиболее значимые группы. В случае приведенного примера ответ очевиден — удалить следует наименьшую из групп.

Начальный фрагмент слова строки поиска расположен внутри слова строки данных
Рассмотрим пример поиска строки ABC в строке XYZAB.
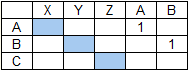
Базовый алгоритм выдаст следующее:
Как правило такой результат не имеет никакой практической ценности и должен быть отброшен.
Недостаточное покрытие слова строки данных найденными фрагментами
В случае поиска в строке ABCDEF слова ABXYZ
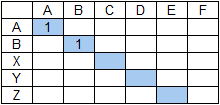
получим:
Этот результат тоже не представляет ценности и должен быть отброшен.
Надгруппы
Даны строка поиска ABCXEF и строка данных ABCEF ABCDEF.
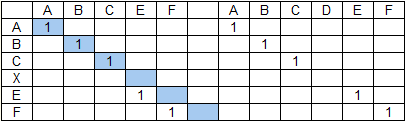
С точки зрения базового алгоритма оба слова строки данных равнозначны, но приоритет будет иметь первое из них (если при прочих равных выбирается первое встретившееся слово) и тогда результат поиска будет следующим:

Если ввести понятие надгруппы как объединения групп слова, расположенных на одной диагонали (или сдвиге, см. предыдущую публикацию, где рассмотрены основы алгоритма) и повысить приоритет входящих в надгруппы групп через параметр размер надгруппы, вычисляемый для каждой из групп и принять при этом, что если группа не входит в надгруппу, то размер надгруппы для нее будет равен размеру самой группы — для нашего примера получим следующий результат:

Завышенная значимость длинных слов
При поиске фразы, содержащей длинное и короткое слово, найденные фрагменты длинного слова могут «затенять» фрагменты короткого. Это связано с использованием квадратичной функции при расчете коэффициента релевантности.
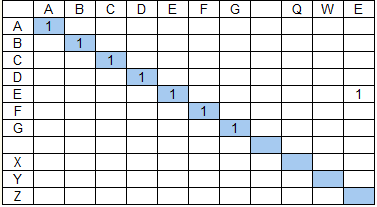
При этом, с точки зрения качества поиска, более длинное слово не всегда является и более значимым. Рассмотрим пример. Пусть нужно найти строку ABCDEFG XYZ в тексте, состоящем из двух страниц:
1. ABCDEFG ... QWE

2. ABCDEFO ... XYZ
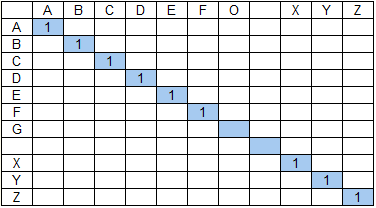

Числитель коэффициента состава групп (знаменатель не оказывает качественного влияния на результат, см. формулу выше) для первой страницы составит 49, для второй — 36 + 9 = 45. То есть, если опустить влияние на результат коэффициента протяженности, то результат поиска на первой странице будет иметь бОльшую релевантность, что не соответствует ожиданиям — в ряде случаев результат поиска на странице 2 будет являться более ценным. Одним из путей решения может быть ввод ограничения на максимальную длину групп. В нашем примере, если максимальную длину групп ограничить к примеру значением 6, то получим для первой страницы 36, для второй — 45, что обеспечит ожидаемый нами результат — релевантность второй страницы будет выше, чем первой. Еще один путь разрешения проблемы несоответствия значимости слов поисковой фразы в общем результате от их длины — расчет релевантности поисковой фразы как среднего от релевантностей входящих в нее слов, вычисленных независимо. Но здесь возникает обратная проблема — необходимости уменьшения значимости коротких слов, которую можно решать аналогичным образом — установкой порогового значения на длину участвующих в формировании общей релевантности слов, но уже на минимальное значение.
Многократные повторения искомых фрагментов
Как следует из постановки, задача состоит в поиске наиболее релевантного строке поиска набора фрагментов, следовательно сам факт многократного повторения искомых фрагментов в тексте не влияет на результат — в качестве результата поиска будет использован первый подходящий фрагмент, остальные отбрасываются в процессе обработки. Рассмотрим пример поиска строки ABC в строке ABCD ABCE ABCF ABCG.

Применение базового алгоритма даст такой результат:

С точки зрения поиска наиболее релевантной страницы это правильно, но при формировании детального представления результатов поиска необходимо найти и выделить все подходящие фрагменты. Для этого можно использовать многократное повторение процедуры поиска по отображаемой странице с последовательным выключением найденных на предыдущих итерациях фрагментов. В нашем примере это позволит найти все подходящие вхождения искомой строки.

Скорость обработки данных
Обработка данных «на лету» предъявляет определенные требования к скорости - поиск не должен происходить слишком долго.
Ограничение минимального размера обрабатываемых групп, отключение опций поиска
Для повышения скорости поиска можно ограничить минимальную длину обрабатываемых групп. На практике применяется следующих подход — сначала делается первый «грубый» проход с ограничением на минимальный размер групп и отключением некоторых опций всего массива данных поиска и выявление первой порции данных (размер оптимальной порции данных определяется из контекста решаемой задачи), а затем второй, более тщательный обход только страниц этой порции, уже без ограничения на размер групп и с включением всех необходимых опций.
Параллельная обработка данных
Еще одной возможностью повышения скорости поиска является параллельная обработка данных. В результате, при большом размере базы поиска, приемлемого общего времени обработки можно достичь увеличением количества параллельных процессов, что естественно потребует наращивания мощности оборудования.
Результаты
Применение описанных подходов позволило существенно повысить качество поиска, снизить зависимость его результатов от различного рода опечаток — лишние, пропущенные символы, перестановки и т.д., причем, что существенно, неважно где находятся эти опечатки — в самой строке поиска или в тексте, в котором осуществляется поиск.
Алгоритм нечеткого поиска TextRadar. Индекс
В продолжение темы оптимизации, далее речь пойдет об индексировании, в первую очередь как средстве ускорения поиска в многостраничных текстах, но не только. В результате мы получим тот же результат, что и с использованием описанных выше подходов, только быстрее.
Предпосылки
Задача поиска фразы в тексте, разбитом на страницы, сводится к расчету коэффициента релевантности для каждой из страниц и последующей сортировке списка в порядке убывания коэффициента. В процессе расчета в соответствии с базовым подходом каждая страница подвергается посимвольному анализу и здесь кроется возможность оптимизации.

При вычислении коэффициента анализируются группы совпадающих символов строк поиска и данных, при этом группы могут образовываться только в рамках слов. С другой стороны, рассматривая проблему завышенной значимости «длинных» слов, в качестве возможного варианта решения предлагался «расчет релевантности поисковой фразы как среднего от релевантностей входящих в нее слов, вычисленных независимо». Использование индекса позволит получить результат, эквивалентный именно этому подходу.
Индекс
Идея индексирования не нова и состоит в следующем - в связи с тем, что слова в тексте повторяются, объем вычислений можно сократить. Для этого по тексту, в котором будет осуществляться поиск, необходимо предварительно сформировать индекс. В простейшем случае индекс представляет собой таблицу всех слов текста, в которой помимо слов содержатся данные о страницах, на которых они встречаются. Фрагмент таблицы индекса, построенного по тексту романа Л.Н. Толстого «Война и мир» (всего в нем содержится порядка 50 тыс. слов), приведен на рисунке.
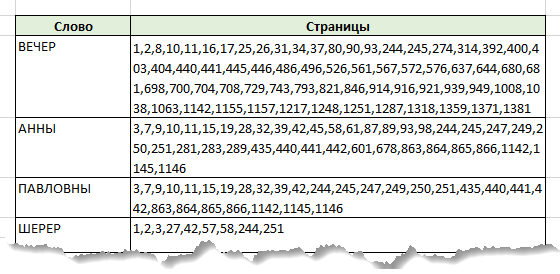
Непосредственно в процессе обработки запроса, строка поиска сначала разбивается на слова. Далее, для каждого из слов строки поиска вычисляется релевантность каждому из слов индекса. Результаты расчета накапливаются в таблице предварительных результатов, содержащей колонки «Слово строки поиска», «Слово индекса», «Коэффициент релевантности», «Номер страницы». В таблицу попадают только те строки индекса, коэффициент релевантности по словам которых превысил заданный порог. То есть, каждая строка индекса с подходящим словом порождает в таблице предварительных результатов строки в количестве, равном числу страниц текста, на которых это слово встречается. Ниже приведен фрагмент таблицы предварительных результатов для поиска фразы «Вечер у Анны Павловны Шерер».
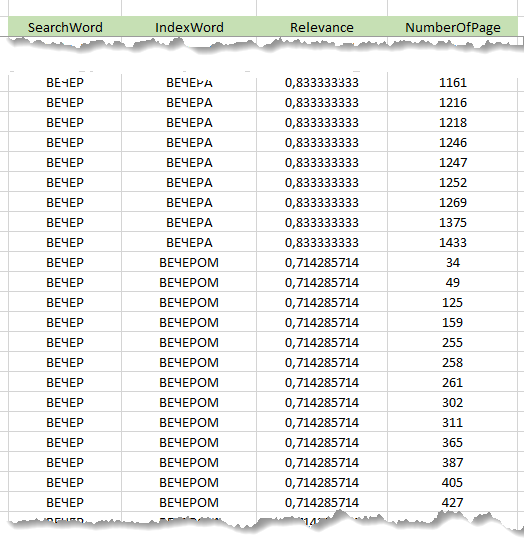
Затем таблица предварительных результатов сортируется по колонкам Номер страницы, Слово строки поиска, Коэффициент (по убыванию).

Обходя строки отсортированной таблицы, по каждой из страниц и для каждого слова строки поиска выявляется наиболее релевантное слово данной страницы – благодаря описанной выше сортировке это первое слово для каждой комбинации Номер страницы – Слово строки поиска. Остальные строки по комбинации отбрасываются.
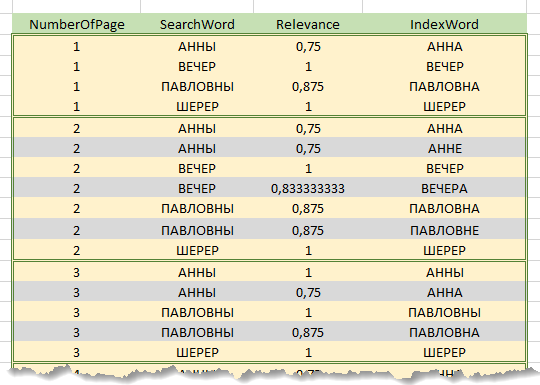
Таким образом, для каждой страницы текста, попавшей в таблицу предварительных результатов, по каждому слову строки поиска будут найдены наиболее релевантные слова этой страницы с соответствующими коэффициентами. Сумма коэффициентов найденных на странице слов, отнесенная к количеству слов в строке поиска, даст коэффициент релевантности для страницы.
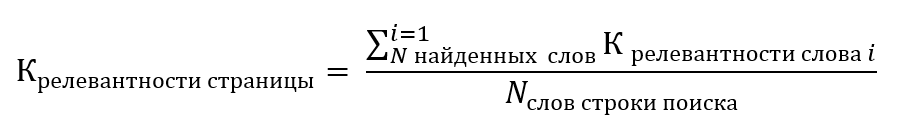
Например, на приведенном выше рисунке, поиск происходит по строке «Вечер у Анны Павловны Шерер» (предлог «у» не учитываем), выделенные серым строки отброшены при обходе. Коэффициент релевантности для страницы 1 будет (0,75 + 1 + 0,875 + 1) / 4 = 0,906, для страницы 2 – 0.906, для 3 – 0.75.
Преимущества
Если не учитывать время, затраченное на индексирование, результаты которого используются многократно и принять во внимание, что общий объем вычислений, оценка которого приводилась в ч. 1, кратен длине строки данных:
;
можно говорить о том, что выигрыш от использования индекса будет кратен отношению:
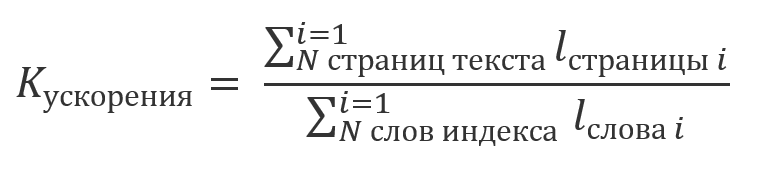
Например, на демо-стенде textradar.ru, текст романа «Война и мир» разбит на 1488 страниц по 2000 символов в каждой. При этом общее количество символов в словах индекса, состоящем из 52156 элементов, составляет 434060. То есть выигрыш от индексирования составит порядка 7:
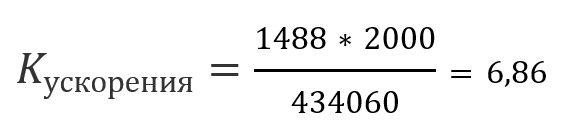
В связи с тем, что результаты, получаемые с помощью индексирования, эквивалентны результатам, получаемым с помощью одного из описанных ранее подходов без него, появляется возможность совместной обработки результатов поиска по проиндексированной и не проиндексированной частям текста. Ввиду того, что индексирование является относительно затратной операцией и обычно выполняется по расписанию, возможна ситуация, когда часть текста проиндексирована, а часть еще нет. В этом случае экономия в объеме вычислений будет кратна доле проиндексированного текста в его общем размере:
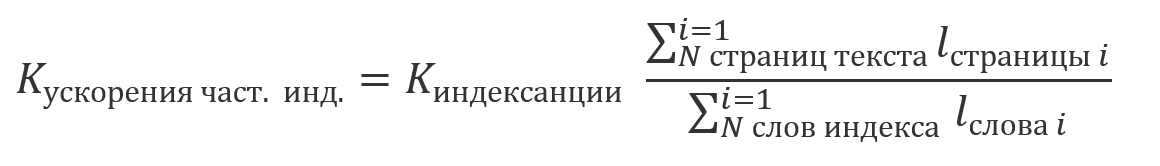
Помимо повышения скорости поиска, использование индекса открывает еще целый ряд возможностей. Например, с помощью статистических данных, полученных при индексировании, можно повысить значимость редких слов, а также выделить страницы текста, на которых слова поисковой фразы встречаются чаще. Также таблицу индекса можно расширить синонимами.
Алгоритм нечеткого поиска TextRadar. Вычисление степени похожести строк
В приведенной выше постановке задачи мы определили роли строк как строка поиска и строка данных. В задаче нечеткого сравнения строк, или вычилсения похожести строк, строки должны быть равнозначны. При этом, если для определения похожести строк (их нечеткого сравнения) применить описанные выше подходы, используя одну сравниваемую строку в качестве строки поиска, а вторую - в качестве строки данных, то в ряде случаев мы получим удовлетворительный результат, но так будет не всегда. Например, если мы будем искать строку "ааа" в "ааа ббб", то получим коэффициент релевантности равный единице, что не соответствует ожиданиям с точки зрения похожести строк. Значит нужно специальное решение. Но можем ли мы использовать описанные выше наработки для решения задачи нечеткого сравнения строк? Как выяснилось - можем.
Постановка задачи
Даны две строки как произвольные наборы символов, состоящие из слов – групп символов, разделенных пробелами. Нужно вычислить похожесть двух строк таким образом, чтобы значение вычисленного коэффициента похожести, равное нулю, свидетельствовало бы об отсутствии похожести, а значению, равному единице - эквивалентности строк, без учета порядка следования слов.
Решение
Как выяснилось в результате практического опыта решения задач по сопоставлению различных списков, для решения задачи вычисления похожести строк достаточно вычислить коэффициенрт релевантности дважды. Первый раз - в качестве строки поиска использовать первую сравниваемую строку, а в качестве строки данных - вторую. Второй раз - поменять строки местами. Коэффициентом похожести будет являться меньший и из двух полученных таким образом коэффициентов.
Алгоритм нечеткого поиска TextRadar. Опции алгоритма
Для придания алгоритму необходимых для решения конкретных практических задач свойств, в алгоритме существуют опции, включающие или отключающее ту или иную функциональность. Ниже приведено описание опций алгоритма.
1. bool СonvertStringsToLowerCase
Преобразовать строки поиска и данных в нижний регистр.
2. bool ReplaceUselessSymbolOfSearchString
Удалить неиспользуемые символы из строки поиска (из строки данных эти символы удаляются всегда). Неиспользуемые символы определяются с помощью функции:
private bool ThisIsUselessSymbol(char Simbol) { return Simbol == '.' || Simbol == ',' || Simbol == ';' || Simbol == '(' || Simbol == ')' || Simbol == '[' || Simbol == ']' || Simbol == '/' || Simbol == '\\' || Simbol == '-' || Simbol == '–' || Simbol == '*' || Simbol == '»' || Simbol == '«' || Simbol == '\"' || Simbol == ':' || Simbol == '?' || Simbol == '!' || Simbol == '…' || Simbol == '\''; }
3. int MinGroupSize
Минимальный размер группы. Если установить минимальный размер группы равным 2, то группы с размером 1 будут игнорироваться, что ускорит формирование расчета. Применяется при первом, грубом обходе больших списков, когда важна скорость расчета.
4. bool DeleteIntersections
Удалять пересечения. Удаление групп, пересекающихся с лучшей группой на очередной итерации.
5. bool ControlConformityAttributeInitialGroupWord
Контролировать соответствие признака групп «Это начальная группа слова». При установке опции в таблицу групп результата попадут только те группы, у которых этот признак совпадает. Использование этой опции исключает ситуацию, когда, например, фрагмент начала слова строки поиска будет найден в середине слова строки данных. При этом, такое поведение нужно не всегда.
6. bool OverGroups
Включение использования механизма надгрупп.
7. bool DeleteIntersectionsGroupsInWordsDataStringAndSearchString
Включение опции обеспечивает то, что группы, найденные в одном слове строки данных, будут принадлежать одному слову строки поиска и наоборот. То есть исключается ситуация, когда, например, фрагменты одного слова строки поиска находятся в нескольких словах строки данных.
8. bool DeleteGroupsOfWordWithoutStartSymbol
Удаление из результата поиска групп по слову строки поиска, которые не включают первый символ слова.
9. bool DeleteGroupsOfWordWithLowCoverege
Удаление из результата поиска групп по слову, отношение суммы квадратов длин которых к квадрату длины слова строки данных, которому эти группы соответствуют, меньше заданного в опции ThresholdOfCoefficientOfCompositionOfGroupsOfWord порога. Здесь следует обратить внимание на то, что корень из вычисляемого описанным выше способом отношения не извлечен, что существенно при установке значения порога.
10. double ThresholdOfCoefficientOfCompositionOfGroupsOfWord
Значения порога для отношения из описания опции DeleteGroupsOfWordWithLowCoverege.
11. bool ConsiderCoefficientOfCoveregeWordByGroup
Учитывать коэффициент покрытия слова группой. Для каждой группы вычисляются коэффициенты покрытия - как отношения длины этой группы (надгруппы) к длинам строки поиска и данных. Вычисленные таким образом коэффициенты влияют на выбор групп при определении состава групп результатов поиска – приоритет имеют группы с наибольшими значениями коэффициентов покрытия.
12. bool RecursiveCalculationOfSearchResult
Рекурсивный расчет результатов поиска. Используется для формирования подробного отображения результата, когда в отображаемый результат попадают не только те фрагменты, которые составили результат поиска, но другие подходящие, но не попавшие в результат фрагменты. Это достигается рекурсивным вызовом процедуры поиска.
13. double ThresholdOfCoefficientWhenRecursiveCalculation
Пороговое значение коэффициента релевантности, при котором рекурсивный поиск прекращается. Используется совместно с опцией RecursiveCalculationOfSearchResult.
14. bool QuickCalculationOfRelevance
Быстрый расчет коэффициента релевантности. Применяется при первом, грубом обходе больших списков, когда важна скорость расчета. Вычисляется ненормированный коэффициент, без учета протяженности результата на строке данных.
15. bool FormingFullRepresentationOfResult
Необходимость формирование подробного представления результатов поиска.
16. bool FormingBriefRepresentationOfResult
Необходимость формирования краткого представления результатов поиска.